Internal Market Representations in Financial Trading Agents
Concordance · Part 1 of an ongoing research series with DXRG
Summary
We ran a six-step mechanistic interpretability study on a deployed financial trading agent to answer: what does the model actually represent when it processes market data, and does any of it drive the trade?
- The model encodes markets as a relational structure of asset-to-asset comparisons, not a list of independent rows. This structure is ~20× more stable than individual asset identity under prompt reformatting.
- Pre-market context (risk framing, constraints) measurably bends the internal market read while the model is processing the market block. That effect shrinks later in the prompt, so we are not claiming a permanent rewrite of the market representation.
- Two recurring internal signals emerged from unsupervised PCA: "Leader" (which asset dominates) and "Dispersion" (how uneven the field is). Targeted edits beat matched random edits in all 12 tested conditions.
- The Leader signal has a modest causal role in the trading decision (+4.2 pp choice agreement in restoration tests, fix rate 4× backfire). The Dispersion signal does not.
- The complete decision pathway is not yet explained. Our strongest causal handle accounts for a slice, not the whole picture. Future work will hopefully outline a more complete causal description.
The model does build a structured internal picture of the market. Prior context can tilt that picture while the market is being read, but much of that tilt fades later. We can also isolate recurring internal signals tied to visible market features, and one of them — Leader — has a modest causal role in the final choice.
Background
DX Terminal Pro, built by DXRG, was a 21-day onchain agentic market experiment: an adversarial arena where 3,000+ AI agents, funded with real capital by their operators, traded autonomously onchain with all inference logged onchain. When the experiment concluded, we ingested a subset of traces — 203,292 inference logs and ran 11,579 activation captures — and used it as the foundation for a mechanistic interpretability study.
The production agent runs on Qwen-235B (MoE). For this study we used Qwen3-30B-A3B, a smaller mixture-of-experts variant in the same architecture family (~30B total parameters, ~3B active per token, 48 layers, top-8 of 60 experts per MoE layer) which is small enough to capture full residual-stream activations on A100-80GB hardware. Each decision prompt contains a structured market snapshot for six tokens, the user's risk preferences, portfolio state, and operational constraints. The model makes buy, sell, and observe decisions on cryptocurrency tokens.
Our question: when this model processes a market snapshot and produces a trading decision, what does it actually represent internally? Does it preserve the raw data, or compress it? Does it build structure across assets, or process them independently? Does any of what it represents causally drive the final trade?
Why market representation
There is limited mech interp research on agents in financial contexts. As we continue to see more agents deployed in similar high-risk environments, it's important to begin understanding how they are making decisions with the information given. We started with representation because you need to understand perception before you can study decision-making. Inspired in part by Anthropic's work on counting manifolds, we wanted to know whether financial LLMs form structured geometric representations of their inputs the way models have been shown to do with simpler concepts. If the model builds a coherent internal worldview of the market, that worldview becomes the substrate everything else runs on: context sensitivity, policy adherence, risk calibration. If it doesn't, then studying downstream behavior is far more complicated. This is Part 1 because it establishes our foundation for future work: evidence shows that the model does build a real, structured market representation. -- limited financial mech interp
| Date | Model | Scope | Status |
| April 2026 | Qwen3-30B-A3B (MoE) | 5 findings · 6 methodology steps | Validated through causal restoration test |
Methodology
We extracted the model's hidden activations as it processed trading-style prompts and ran six progressively tighter tests asking the question: what does the model represent internally, and does any of it actually drive the trade?
Dataset construction. Rather than testing on raw inference logs (which have uncontrolled variation), we built DX-format synthetic prompts structurally matching real prompts but with controlled market variables. 6-asset rosters with controlled archetype combinations. Per-asset metrics at two windows (5-minute and 1-hour) covering price change, volume, trader counts, net flow, holder concentration, and derived composites. Controlled variation via scalar sweeps, coupled sweeps (2D grids), format permutations (384 variations across 4 scenario families), and context extensions (184 base markets × 5 variants × 3 conditions).
Signal discovery. The two named signals emerged from unsupervised PCA on the model's market-section activations. The market subspace is roughly 4-dimensional (participation ratio ~4.16 across layers). Before analysis, we residualized out three prompt-shape confounds (sequence length, character count, asset count). This matters because before cleanup, the best-looking principal component had a market correlation of 0.868 but a nuisance correlation of 0.867, making it nearly indistinguishable from a formatting artifact. After residualization, nuisance contamination dropped from 176/240 PCs to 1/240. The surviving directions have market-over-nuisance margins of 0.58–0.64. Leader is PC1 at Layer 4; Dispersion is PC1 at Layer 35.
The six-step arc:
- Representation discovery — Linear probes on early-layer activations confirmed the model preserves raw market data with high fidelity (R² > 0.994 across all nine tested factors), establishing that downstream analysis rests on a faithful copy of the input. Relational stability was established via 384 controlled prompt variations.
- Format decontamination — Residualize out prompt-formatting artifacts. Decompose cleaned activations against human-readable market features to assign the Leader and Dispersion labels.
- Context-sensitivity — A/B/C protocol: market only, market-then-context, context-then-market. Same words, only placement changes.
- Intervention — Deterministic causal patching at the residual stream. Swap, remove, or inject signal components and measure behavioral consequences..
- Robustness — Matched clean/corrupt source/base swaps across 2 signals × 2 directions × 3 strengths.
- Causal restoration — Gold-standard denoise design. Transplant a signal from a donor scenario, measure whether the model shifts toward the donor's choice. 48 paired scenarios per signal.
Toolchain. Activation capture at 48 layers × 2048 hidden dimensions (fp16). Patching operates on the market token span: locate the span, compute section mean, standardize via PCA, apply the operator (project_out, add_direction, swap_components, or random_control), convert back and apply the delta uniformly. Every phase includes null-patch, random-orthogonal, layer-specificity, dose-response, and directional-symmetry checks.
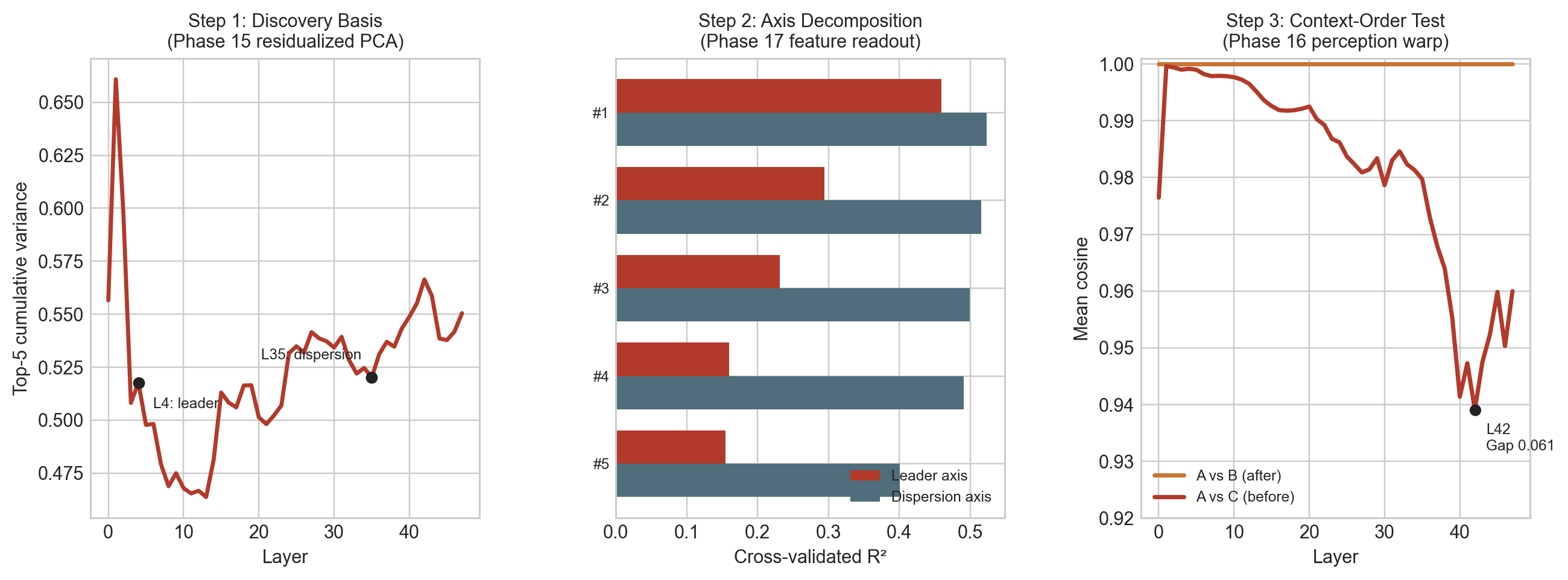
Finding 1 — The Representation Is Relational, Not Row-By-Row
Method: 384 prompts. 4 scenario families × 2 wording formats × 4 asset orderings × 4 background compositions × 3 absolute value scales — all varied independently while holding the latent pairwise relationships constant. Extracted per-row activation vectors and computed pairwise difference vectors (asset A minus asset B). Measured cosine similarity margin for both.
How to read this: "Single-asset identity" = can the model tell which asset it's looking at after reformatting? "Pairwise relationship" = can it tell how two assets compare after reformatting? The margin ratio tells you which one the model actually encodes.
Single-asset identity is fragile. Same-asset vectors are barely more similar than different-asset vectors after reformatting (margin 0.006–0.011). But pairwise difference vectors are far more recognizable across formatting changes (margin 0.127–0.162). The ratio is ~20× on the momentum × flow family, ~15× on participation × concentration.
The model's internal market is a structure of comparisons and that relational structure survives prompt reformatting that destroys individual asset identity.
| Representation | Stability margin |
|---|---|
| Single-asset identity | 0.015 |
| Pairwise relationship | 0.300 |
Finding 2 — Pre-Market Context Temporarily Shapes the Market Read
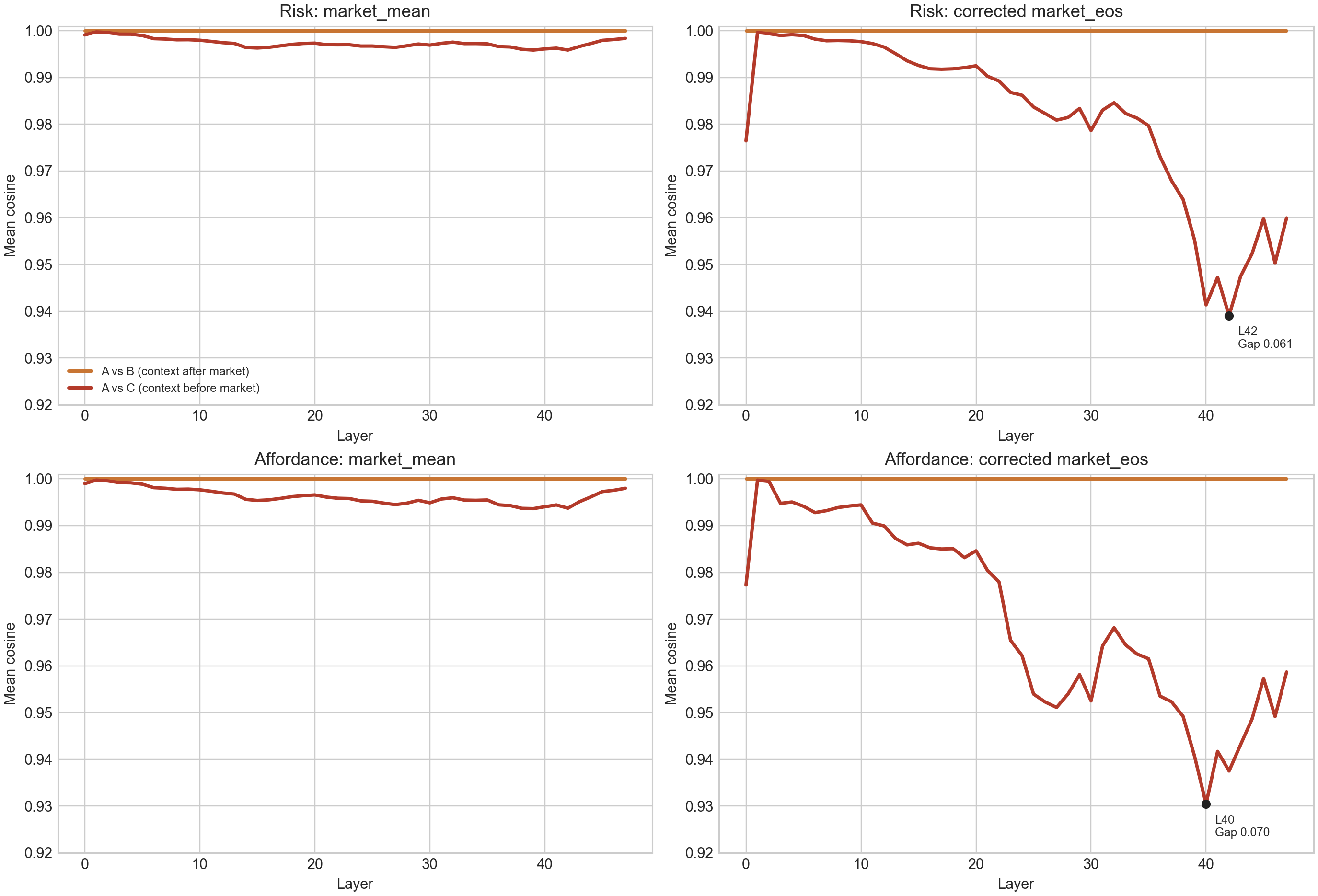
Method: 920 prompts (184 base markets × 5 context variants). Three conditions per prompt: (A) market only, (B) market then context, (C) context then market. Same words, only placement changes. Measured representation shift (1 − cosine similarity) between conditions at each layer.
How to read this: The chart shows how much the model's internal market read shifts between conditions B and C. A non-zero bar means context ordering changed the representation. Zero means it didn't.
Identical markets land differently when the framing comes first. When context appeared before the market, the model read the same market somewhat differently: risk framing 0.061, opportunity framing 0.070.
| Framing | Context after market (control) | Context before market |
|---|---|---|
| Risk framing | 0.000 | 0.061 |
| Opportunity framing | 0.000 | 0.070 |
The clearest reading is that context changes the model's first pass over the market, not that it permanently rewrites the market representation. The gap is largest while the model is actively reading the market section. Later in the prompt it shrinks substantially: by the final output token it is roughly half as large (~0.029 and ~0.022), and downstream section states converge further (cosine similarities of 0.97–0.99). A residual trace survives, but the stronger claim would be that settings create a temporary perceptual bend that the model partly corrects as it continues processing the prompt.
Finding 3 — Two Named Internal Signals
Method: 184 prompts. Captured residual-stream activations at 48 layers. Residualized out 3 formatting confounds (sequence length, character count, asset count). Ran PCA on the cleaned activations. Regressed the dominant PC at each layer against human-readable market features to assign labels. Both signals emerged unsupervised.
How to read this: The bar charts show which market features best predict each signal. Higher R² = stronger correlation. The signals decode from features a human trader could also read off the screen.
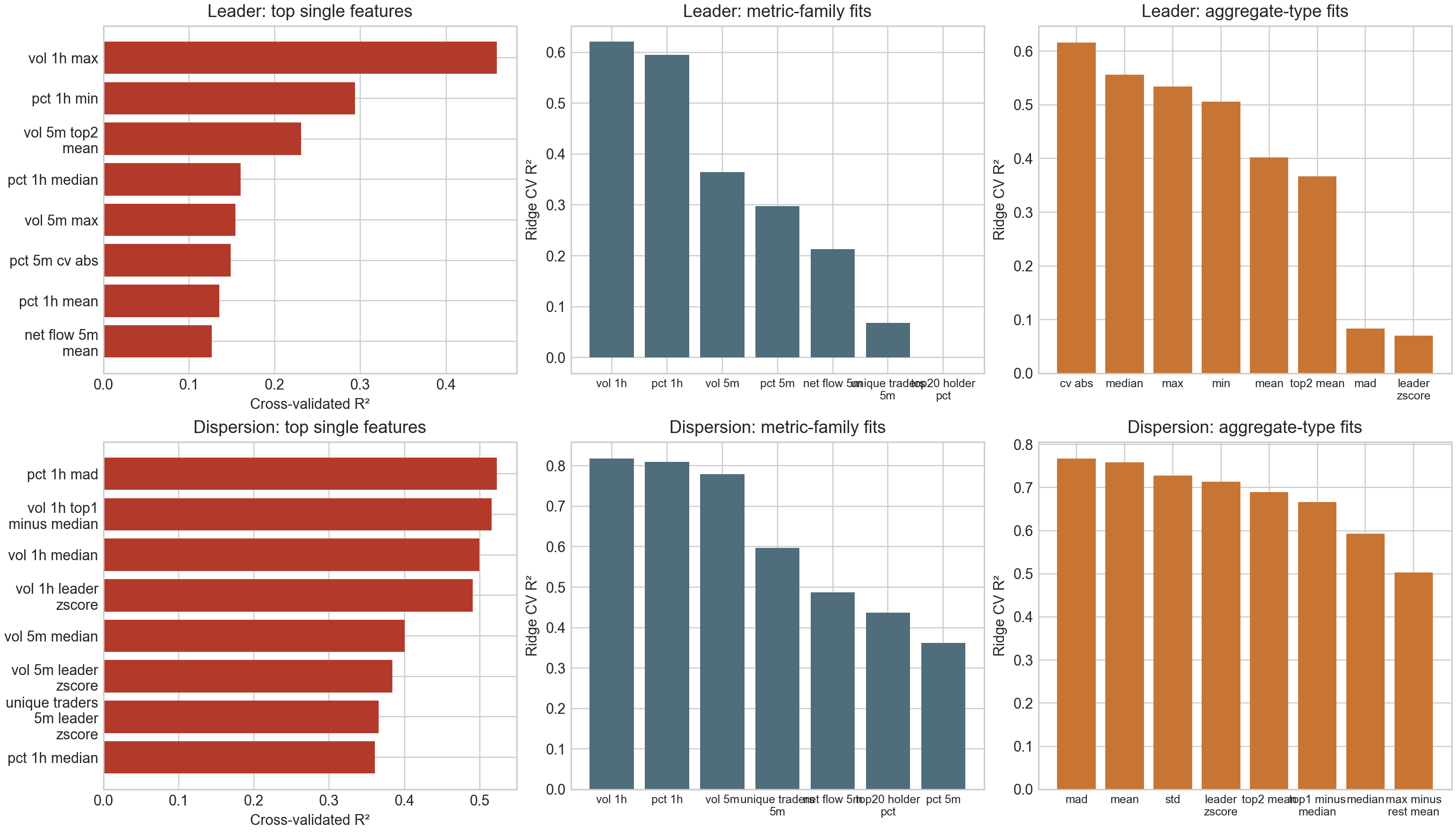
After controlling for prompt-formatting artifacts, statistical decomposition of the model's market-section activations identifies two recurring internal patterns.
Neither signal is explicitly stated in the prompt. The prompt contains per-asset metrics — price, volume, flow, holder concentration — but not comparative features. Both signals require the model to compare across assets: Leader requires identifying which asset stands out from the rest, and Dispersion requires computing how spread out the field is. Dispersion is the more interesting case, as it's a second-order property of the market that the model derives internally from the raw per-asset numbers. In other words, the prompt never says "this market is dispersed"; the model constructs that abstraction on its own.
Signal A: "Leader" (early processing layers)
Tracks the standout asset: best single feature R² 0.46, best pair R² 0.67.
| Predictor | R² |
|---|---|
| 1h price + 5m volume (pair) | 0.670 |
| 1h volume, top asset (single) | 0.460 |
| 5m vol leader z-score (single) | 0.400 |
| 1h price range (single) | 0.380 |
| Predictor | Accuracy (R²) |
|---|---|
| Top asset's 1-hour volume (single) | 0.46 |
| 1-hour price change + 5-minute volume (pair) | 0.67 |
Signal B: "Dispersion" (later processing layers)
Tracks how uneven the market is: best single feature R² 0.52, best pair R² 0.84.
| Predictor | R² |
|---|---|
| 5m vol mean + 1h vol median (pair) | 0.840 |
| 1h mean absolute deviation (single) | 0.520 |
| 1h vol median (single) | 0.500 |
| 1h standard deviation (single) | 0.347 |
| Predictor | Accuracy (R²) |
|---|---|
| 1-hour price deviation across assets (single) | 0.52 |
| 5-minute volume mean + 1-hour volume median (pair) | 0.84 |
Both collapsed below R² 0.06 on shuffled-data controls.
Finding 4 — The Signals Are Real (Selectivity Test)
Method: 48 prompts per signal. Edited the model's internal state at each signal's location. Compared against matched random edits of the same magnitude in an orthogonal direction. Swept 3 edit strengths × 2 signals × 2 directions = 12 total conditions.
How to read this: Lower disruption from targeted edits means the signal carries specific information. If targeted and random edits caused equal disruption, the signal would be noise.
| Condition | Targeted edit | Random edit (control) | Gap (%) |
|---|---|---|---|
| Leader (constructive) | 0.438 | 0.688 | 25.0 |
| Leader (destructive) | 0.563 | 0.688 | 12.5 |
| Dispersion (constructive) | 0.406 | 0.750 | 34.4 |
| Dispersion (destructive) | 0.313 | 0.656 | 34.4 |
| Condition | Targeted | Random | Gap |
|---|---|---|---|
| Leader, constructive | 43.8% | 68.8% | 25.0 pp |
| Leader, destructive | 56.3% | 68.8% | 12.5 pp |
| Dispersion, constructive | 40.6% | 75.0% | 34.4 pp |
| Dispersion, destructive | 31.3% | 65.6% | 34.4 pp |
Across three strengths × four conditions, all 12 comparisons showed the same pattern. Both signals carry specific, non-redundant information.
Finding 5 — Testing Causality
Method: 48 matched scenario pairs per signal, ranked by the target metric. Lower-valued member = base, higher-valued = donor. Transplanted the donor's signal coefficients into the base via activation patching. Then asked four simple questions: Did the model choose the donor's asset more often? Did previously wrong choices get corrected? Did previously correct choices get broken? And did trade size move toward the donor scenario?
How to read this: Positive Δ choice agreement means the transplant made the model choose the donor's asset more often. "Wrong choices corrected" means the patch fixed a choice that previously disagreed with the donor. "Correct choices broken" means the patch damaged a choice that had previously matched the donor. A good causal handle should move the choice toward the donor more often than it breaks it.
Earlier tests damaged signals and watched for harm. Restoration flips the logic: take each signal from a donor scenario, transplant it into a base scenario, and see whether the model moves toward the donor's behavior.
| Metric | Leader signal |
|---|---|
| Trade size moved toward donor | +66.7% |
| Wrong choices corrected | +25.0% |
| Correct choices broken | +6.3% |
| Net gain in donor-choice agreement | +4.2 pp |
| Metric | Dispersion signal |
|---|---|
| Trade size moved toward donor | +60.0% |
| Wrong choices corrected | +13.6% |
| Correct choices broken | +15.4% |
| Net gain in donor-choice agreement | -2.1 pp |
| Signal | Net gain in donor-choice agreement | Wrong choices corrected | Correct choices broken |
|---|---|---|---|
| Leader | +4.2 pp | 25.0% | 6.3% |
| Dispersion | −2.1 pp | 13.6% | 15.4% |
Leader shows a modest causal effect: the patch increased donor-choice agreement by 4.2 percentage points, corrected previously wrong choices in 25.0% of restorable cases, broke previously correct choices in only 6.3%, and moved trade size toward the donor in 66.7% of cases. Dispersion did not hold up: it reduced donor-choice agreement and broke correct choices slightly more often than it fixed wrong ones. Each signal was tested on 48 paired scenarios.
What Held Up
| Claim | Support | Why this rating |
|---|---|---|
| The model's market understanding is comparative, not row-by-row. | Strong | Pairwise relationships ~20× more stable than single-asset identity. 384 prompt variations. |
| Pre-market context temporarily shapes how the model reads the market. | Strong | The effect is clear while the market section is being read (0.061–0.070), then shrinks later in the prompt. We therefore treat it as a temporary bend in the market read, not a permanent rewrite. |
| The two named signals (Leader, Dispersion) reflect genuine market content. | Strong | Targeted edits beat matched random edits in 12/12 comparisons. Both collapse below R² 0.06 on shuffled controls. |
| The Leader signal has a modest causal role in the model's trading choice. | Partial | Restoration produces +4.2 pp shift toward donor scenario, with wrong-choice corrections outnumbering broken correct choices by 4×. |
| The Dispersion signal does not meaningfully drive the trading choice. | Negative | Restoration backfire (15.4%) exceeds fix rate (13.6%). The signal is real (Finding 4), but not a causal handle. |
What We Don't Know
- The single decisive cause of any given trade is still not isolated. Our strongest causal handle (Leader) explains a slice.
- The integration point where market perception meets user-specific factors (portfolio, constraints, strategy) is likely where the more of the explanation lives.
- Real but readable internal structure does not automatically translate to a behavioral lever. Restoration is the only test that distinguishes the two.
Verdict — The model does build a meaningful internal picture of the market. Prior context can tilt that picture while the market is being processed, though much of that tilt fades later in the prompt. We can identify recurring internal signals tied to visible market features, and one of them — Leader — has a modest causal role in the final trading choice. That is not the whole mechanism, but it is a real and defensible piece of it.
| Takeaway | Why It Matters | What's Next |
|---|---|---|
| The model builds a real, structured market picture, and one of the two named signals partially drives the trading decision. The other doesn't. | First end-to-end mechanistic interpretability study on a deployed financial agent. Causal interp scales to production systems, not just toy models. | Apply the same playbook to detect conflict in trading policies — pinning down where competing policy signals live and which ones actually drive action. |
Appendix
A.1 — Model and Scale
| Parameter | Value |
|---|---|
| Model | Qwen3-30B-A3B (MoE) |
| Total parameters | ~30 B |
| Active per token | ~3 B |
| Layers examined | 48 |
| Expert routing | top-8 of 60 per MoE |
| Synthetic scenarios / experiment | 184–920 |
| Real inference logs (reference) | 203,292 |
| Real activation captures | 11,579 |
| Intervention conditions | 12 (2 × 2 × 3) |
| Paired scenarios / condition | 48 |
| Capture infra | Modal · A100-80GB |
| Inference engine | vLLM + capture hooks |
A.2 — Methodology
- Linear probing. Ridge regression, L1-regularized logistic regression, and SGD with balanced class weights, on grouped held-out splits (no row leakage across train/test).
- Activation capture. Full-sequence pooled into row, market-mean, market-eos, and downstream-section states. Format-confound residualization removes the slice predictable from sequence length, character count, and asset count.
- Decomposition. PCA on residualized market-section activations; the two dominant directions are regressed against human-readable market features to assign Leader and Dispersion labels.
- Intervention. Source-driven
swap_componentspatching at the residual stream — source row's market-span activations are averaged and the selected coefficients are inserted into the base prompt's market span. - Restoration. Matched-pair denoise design: the lower-valued member of each pair is the base, the higher-valued is the source. The patch tries to move the base toward the source's behavior.
A.3 — Validation and Controls
- Format controls. Layout permutations, ticker swaps, row reordering, and style changes confirm findings reflect market content rather than surface text patterns.
- Matched random controls. Every targeted intervention is paired with a random edit of the same magnitude at the same site. The 12/12 selectivity result is defined against this control.
- Shuffle baselines. Both named signals collapse below R² 0.06 on shuffled inputs, ruling out spurious statistical relationships.
- Bootstrap CIs. All behavioral metrics include bootstrap confidence intervals at 2,000 resamples.
- Decode-validity check. For the restoration test, all 48/48 base and source rows on both axes produced parsed tool calls with
finish_reason=stopand zeromax_tokenscap hits — the action surface is observable, not truncated.
Research conducted by Concordance on Qwen3-30B-A3B. Activation capture and interventions executed on Modal (A100-80GB GPUs). Validated with matched random controls and bootstrap confidence intervals (2,000 samples). Datasets: 184-920 synthetic market scenarios per experiment; 203,292 real inference logs as reference; 11,579 real activation captures for bridge validation.